Built for high throughput and low latency, Amazon CloudSearch supports a rich set of features including language-specific text processing for 34 languages, free text search, faceted search, geospatial search, customizable relevance ranking, highlighting, autocomplete and user configurable scaling and availability options.
To use Amazon CloudSearch, you follow these simple steps:
- Create a search domain
- Configure indexing options for your data
- Upload your data for indexing
- Submit search requests from your website or application
In the section below, you will find details about how CloudSearch works.
Try Amazon CloudSearch for free
Start CloudSearch Free TrialLearn More
Get 750 free hours of fully functional search instances for 30 days. To start:
Sign in to your AWS account and launch the CloudSearch Console
Create and configure a search domain with a few clicks
You create an Amazon CloudSearch search domain for each collection of data that you want to make searchable. A search domain encapsulates your data and the hardware and software resources required to operate a search engine. Each search domain has one or more search instances. A search instance is a server instance that has a finite amount of RAM and CPU resources for indexing data and processing requests. The number of search instances in a domain depends on the documents in your collection and the volume and complexity of your search requests.
As a managed search service, Amazon CloudSearch determines the size and number of search instances required to deliver low latency, high throughput search performance. When you create a search domain, by default Amazon CloudSearch uses a Small search instance type (search.m1.small). You can select a larger search instance type to boost your domain's update capacity and reduce the amount of time it takes to upload and index a large collection of data. (If you need more capacity than the largest instance type offers, you can increase the number of instances that your index is partitioned across.)
As the amount of data in your search index grows, Amazon CloudSearch automatically scales your search domain as needed. When your index exceeds the capacity of the current instance type, the domain is scaled to the next larger instance type. If your search index exceeds the capacity of the largest instance type, Amazon CloudSearch partitions the index across multiple instances. Conversely, if your index shrinks, CloudSearch scales your domain down to fewer partitions or a smaller search instance type.
Amazon CloudSearch also automatically scales to handle increases in the amount of search traffic. When a search instance nears its maximum query load, CloudSearch deploys a replica of the search instance. Conversely, when search traffic drops, Amazon CloudSearch removes unneeded replicas to minimize costs.
For example, a search index that is split into three partitions uses three search instances (one for each partition). As search traffic increases beyond the processing capacity of the individual search instances, the partitions are replicated to provide additional query capacity. Once the instances are replicated, the domain has a total of six search instances—two for each partition. If traffic continues to increase, Amazon CloudSearch adds more replicas as needed.
If you expect a large amount of query traffic or a significant spike in traffic, you can explicitly add search instance replicas to your domain.

You can view the resources that your Amazon CloudSearch domains are using from the Account Activity page on the AWS website, through the AWS Management Console, or by submitting CloudSearch API requests through the AWS CLI or AWS SDKs.
The amount of data that each search instance type can support mostly depends on the size of the documents you are indexing and the indexing options configured for your domain.
To demonstrate the capacity of each search instance type, let's look at a sample document and configuration for the IMDb Movies data set. The following example shows an IMDb movie document that is approximately 1 KB in size:
{
"fields" : {
"directors" : [
"Francis Lawrence"
],
"release_date" : "2013-11-11T00:00:00Z",
"genres" : [
"Action",
"Adventure",
"Sci-Fi",
"Thriller"
],
"image_url" : "http://ia.media-imdb.com/images/M/MV5xMzNeMzAx._V1_SX400_.jpg",
"plot" : "Katniss Everdeen and Peeta Mellark become targets of the Capitol after their victory in the 74th Hunger Games sparks a rebellion in the Districts of Panem.","title" : "The Hunger Games: Catching Fire",
"rank" : 4,
"running_time_secs" : 8760,
"actors" : [
"Jennifer Lawrence",
"Josh Hutcherson",
"Liam Hemsworth"
],
"year" : 2013
},
"id" : "tt1951264",
"type" : "add"
}
To index and search movie documents like this one, we configure our search domain with an index field for each document field. We can specify multiple indexing options for each field, such as the type of the field and whether the field is searchable, facet enabled, return enabled, sort enabled, and highlight enabled. These indexing options directly impact how many documents fit onto a search instance. The following table shows a sample configuration for the index fields for our IMDb movies documents.
| Name |
Type |
Search |
Facet |
Return |
Sort | Highlight |
|---|---|---|---|---|---|---|
| actors |
text-array |
✔ | — | ✗ | — | ✗ |
| directors |
text-array |
✔ | — | ✗ | — | ✗ |
| genres |
literal-array |
✔ | ✔ | ✗ |
— | — |
| image_url |
text |
✗ | — | ✗ | ✗ | ✗ |
| plot |
text |
✔ | — | ✗ | ✗ | ✔ |
| rank | int | ✔ | ✗ | ✗ | ✔ | — |
| rating |
double |
✔ | ✔ | ✗ | ✔ | — |
| release_date |
date |
✔ | ✔ | ✗ | ✔ | — |
| running_time_secs |
int |
✔ | ✔ | ✗ | ✔ | — |
| title |
text |
✔ | — | ✔ | ✔ | ✔ |
| year |
int |
✔ | ✔ | ✔ | ✔ | — |
Based on the document size (1 KB) and this index configuration, each search instance type has the document capacity shown in the following table.
| Search Instance Type | Data Capacity |
|---|---|
| Small Search Instance (search.m1.small) |
2 million documents |
| Large Search Instance (search.m1.large) | 8 million documents |
| Extra Large Search Instance (search.m2.xlarge) |
16 million documents |
| Double Extra Large Search Instance (search.m2.2xlarge) | 32 million documents |
Of course, this is just one example. Different documents and different configurations can dramatically change the number of documents that fit on an instance. If you exceed the capacity of a single Double Extra Large Search Instance, Amazon CloudSearch automatically partitions your search index across additional Double Extra large Search Instances. An index can be partitioned across up to 10 Double Extra Large Search Instances to support tens or hundreds of millions of documents. If you require additional scaling, contact us.
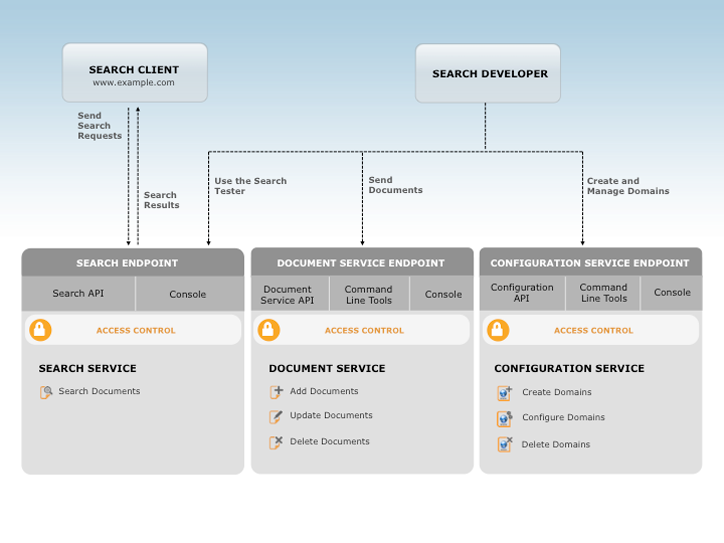
You interact with Amazon CloudSearch through three services:
- Configuration service—create and configure search domains
- Document service—upload document batches
- Search service—submit search and suggestion requests
You use AWS Identity and Access Management (IAM) policies to manage access to the Amazon CloudSearch configuration service and each domain’s document and search services.
The configuration service enables you to create and configure search domains. To set up a search domain, you give it a unique name and configure indexing options, text analysis schemes, availability options, scaling options, suggesters, and expressions:
- Indexing options specify the fields you want to include in your index. You can use the AWS Management Console or the Amazon CloudSearch command line tools to scan your data and automatically configure default indexing options.
- Text analysis schemes specify language-specific text processing options for text and text-array fields. Analysis schemes control the stopwords that should be ignored during indexing, define common synonyms for terms, and specify how terms are mapped to common stems.
- Availability options enable you to deploy a domain across two Availability Zones to ensure high availability in the event of a service disruption.
- Scaling options enable you to prescale your domain by specifying the desired instance type, replication count, and partition count. This is useful when you need to upload a large volume of documents or anticipate a significant increase in query traffic.
- Suggesters enable you to retrieve possible matches for an incomplete search query so you can display results as the user types.
- Expressions are numeric expressions that are evaluated at query time. You can use expressions to control how search results are ranked. By default, documents are ranked by a relevance score that takes into account the frequency of the search terms within a document. You can use expressions to include other factors in the ranking. For example, if your documents contain a numeric field called "popularity," you could define an expression that combines popularity with the default relevance score to rank relevant popular documents higher in your search results.
You use the document service to make changes to a domain's searchable data. Each domain has a unique document service HTTP endpoint.
To send data to your domain, you need to format it in JSON or XML. Each item that you want to be able to return as a search result is represented as a document. Every document has a unique ID and one or more fields that contain the data that you want to search and return in results. Document fields can contain any UTF-8 string data. Your domain's indexing options specify how you want to index and use the data.
The search service handles search and suggestion requests for a domain. Each domain has a unique search HTTP endpoint. When you send a search or suggest request, the search service returns a list of matching documents. Results can be returned in either JSON or XML.
Amazon CloudSearch provides a rich query language that enables you to search within particular fields, perform complex Boolean searches, retrieve facet information, and specify what data you want the results to include. You can also specify options to control how query terms are processed and use other query parsers such as the Lucene or DisMax parser.
You can use the search tester in the Amazon CloudSearch console to test sample queries.
Your use of this service is subject to the Amazon Web Services Customer Agreement.