



¿Qué es el aprendizaje mediante refuerzo?
El aprendizaje por refuerzo (RL) es una técnica de machine learning (ML) que entrena al software para que tome decisiones y logre los mejores resultados. Imita el proceso de aprendizaje por ensayo y error que los humanos utilizan para lograr sus objetivos. Las acciones de software que trabajan para alcanzar su objetivo se refuerzan, mientras que las que se apartan del objetivo se ignoran.
Los algoritmos de RL utilizan un paradigma de recompensa y castigo al procesar los datos. Aprenden de los comentarios de cada acción y descubren por sí mismos las mejores rutas de procesamiento para lograr los resultados finales. Los algoritmos también son capaces de funcionar con gratificación aplazada. La mejor estrategia general puede requerir sacrificios a corto plazo, por lo que el mejor enfoque descubierto puede incluir algunos castigos o dar marcha atrás en el camino. El RL es un potente método que ayuda a los sistemas de inteligencia artificial (IA) a lograr resultados óptimos en entornos invisibles.
¿Cuáles son los beneficios del aprendizaje por refuerzo?
El uso del aprendizaje por refuerzo (RL) tiene muchos beneficios. Sin embargo, los más destacados son los tres indicados a continuación.
Sobresale en entornos complejos
Los algoritmos de RL se pueden utilizar en entornos complejos con muchas reglas y dependencias. En el mismo entorno, es posible que un ser humano no sea capaz de determinar el mejor camino a seguir, incluso con un conocimiento superior del entorno. En cambio, los algoritmos de RL sin modelo se adaptan rápidamente a entornos que cambian continuamente y encuentran nuevas estrategias para optimizar los resultados.
Requiere menos interacción humana
En el caso de los algoritmos de ML tradicionales, se necesitan personas que etiqueten pares de datos para dirigir el algoritmo. Cuando se utiliza un algoritmo de RL, esto no es necesario. El algoritmo aprende por sí mismo. Al mismo tiempo, ofrece mecanismos para integrar la retroalimentación humana, lo que permite crear sistemas que se adapten a las preferencias, la experiencia y las correcciones humanas.
Optimiza de acuerdo con objetivos a largo plazo
El RL se centra intrínsecamente en la maximización de las recompensas a largo plazo, lo que lo hace apto para escenarios en los que las acciones tienen consecuencias prolongadas. Es especialmente adecuado para situaciones del mundo real en las que no hay retroalimentación disponible de inmediato para cada paso, ya que puede aprender de las recompensas retrasadas.
Por ejemplo, las decisiones sobre el consumo o el almacenamiento de energía pueden tener consecuencias a largo plazo. El RL se puede utilizar para optimizar la eficiencia energética y los costos a largo plazo. Con las arquitecturas adecuadas, los agentes de RL también pueden generalizar sus estrategias aprendidas en tareas similares pero no idénticas.
¿Cuáles son los casos de uso del aprendizaje por refuerzo?
El aprendizaje por refuerzo (RL) se puede aplicar a una amplia gama de casos de uso del mundo real. A continuación, presentamos algunos ejemplos.
Personalización de marketing
En aplicaciones como los sistemas de recomendación, el RL puede personalizar las sugerencias para los usuarios individuales en función de sus interacciones. Esto lleva a experiencias más personalizadas. Por ejemplo, una aplicación puede mostrar anuncios a un usuario en función de cierta información demográfica. Con cada interacción publicitaria, la aplicación aprende qué anuncios mostrar al usuario para optimizar las ventas de productos.
Desafíos de optimización
Los métodos de optimización tradicionales resuelven los problemas mediante la evaluación y comparación de las posibles soluciones en función de ciertos criterios. Por el contrario, el RL introduce el aprendizaje a partir de las interacciones para encontrar las mejores soluciones (o las más cercanas a las mejores) a lo largo del tiempo.
Por ejemplo, un sistema de optimización del gasto en la nube utiliza el RL para adaptarse a las necesidades de recursos fluctuantes y elegir los tipos, cantidades y configuraciones de instancias óptimos. Toma decisiones en función de factores como la infraestructura de nube actual y disponible, los gastos y la utilización.
Predicciones financieras
La dinámica de los mercados financieros es compleja, con propiedades estadísticas que cambian con el tiempo. Los algoritmos de RL pueden optimizar los rendimientos a largo plazo al considerar los costos de transacción y adaptarse a los cambios del mercado.
Por ejemplo, un algoritmo podría observar las reglas y los patrones del mercado de valores antes de probar las acciones y registrar las recompensas asociadas. El algoritmo crea una función de valor y desarrolla una estrategia para maximizar las ganancias.
¿Cómo funciona el aprendizaje por refuerzo?
El proceso de aprendizaje de los algoritmos de aprendizaje por refuerzo (RL) es similar al aprendizaje por refuerzo animal y humano en el campo de la psicología del comportamiento. Por ejemplo, un niño puede descubrir que recibe elogios de sus padres cuando ayuda a un hermano o a limpiar, pero recibe reacciones negativas cuando tira juguetes o grita. Pronto, el niño aprende qué combinación de actividades trae como resultado la recompensa final.
Un algoritmo RL imita un proceso de aprendizaje similar. Prueba diferentes actividades para aprender los valores negativos y positivos asociados para lograr el resultado final de la recompensa.
Conceptos clave
En el aprendizaje por refuerzo, hay algunos conceptos clave con los que debe familiarizarse:
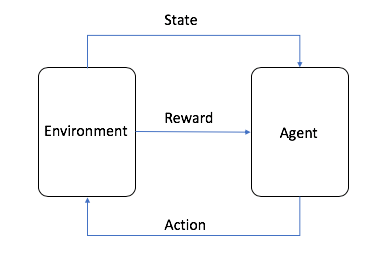
- El agente es el algoritmo ML (o el sistema autónomo)
- El entorno es el espacio de problemas adaptativo con atributos como variables, valores límite, reglas y acciones válidas
- La acción es un paso que el agente de RL realiza para navegar por el entorno
- El estado es el medio ambiente en un momento dado
- La recompensa es el valor positivo, negativo o cero (en otras palabras, la recompensa o el castigo) por llevar a cabo una acción
- La recompensa acumulada es la suma de todas las recompensas o el valor final
Conceptos básicos de algoritmos
El aprendizaje por refuerzo se basa en el proceso de decisión de Markov, un modelo matemático de la toma de decisiones que utiliza intervalos de tiempo discretos. En cada paso, el agente lleva a cabo una nueva acción que da como resultado un nuevo estado del entorno. Del mismo modo, el estado actual se atribuye a la secuencia de acciones anteriores.
Mediante prueba y error y su movimiento por el entorno, el agente crea un conjunto de reglas o políticas “condicionales”. Las políticas ayudan a decidir qué acción tomar a continuación para obtener una recompensa acumulada óptima. El agente también debe elegir entre seguir explorando el entorno para obtener nuevas recompensas de estado-acción o seleccionar acciones conocidas con altas recompensas de un estado determinado. Esto se denomina compensación entre exploración y explotación.
¿Cuáles son los tipos de algoritmos de aprendizaje por refuerzo?
Hay varios algoritmos que se utilizan en el aprendizaje por refuerzo (RL), como el Q-learning, los métodos de gradiente de políticas, los métodos de Montecarlo y el aprendizaje por diferencia temporal. El RL profundo es la aplicación de redes neuronales profundas al aprendizaje por refuerzo. Un ejemplo de un algoritmo de RL profundo es la optimización de políticas de región de confianza (TRPO).
Todos estos algoritmos se pueden agrupar en dos amplias categorías.
RL basado en modelos
El RL basado en modelos se suele utilizar cuando los entornos están bien definidos y no cambian y cuando las pruebas en entornos reales son difíciles de realizar.
Primero, el agente crea una representación interna (modelo) del entorno. Utiliza este proceso para crear dicho modelo:
- Toma medidas en el entorno y observa el nuevo estado y el valor de la recompensa
- Asocia la transición de acción-estado con el valor de la recompensa.
Una vez que el modelo está completo, el agente simula las secuencias de acción en función de la probabilidad de obtener recompensas acumuladas óptimas. A continuación, asigna valores a las propias secuencias de acción. De este modo, el agente desarrolla diferentes estrategias dentro del entorno para lograr el objetivo final deseado.
Ejemplo
Pensemos en un robot que aprende a moverse por un edificio nuevo para llegar a una habitación específica. Inicialmente, el robot explora libremente y construye un modelo interno (o mapa) del edificio. Por ejemplo, podría aprender al descubrir un ascensor después de avanzar 10 metros desde la entrada principal. Una vez que crea el mapa, puede crear una serie de secuencias de rutas más cortas entre las diferentes ubicaciones que visita con frecuencia dentro del edificio.
RL sin modelo
Es mejor usar el RL sin modelos cuando el entorno es grande, complejo y no se puede describir fácilmente. También es ideal cuando el entorno es desconocido y cambiante, y las pruebas basadas en el entorno no presentan desventajas significativas.
El agente no construye un modelo interno del entorno y su dinámica. En su lugar, utiliza un enfoque de prueba y error dentro del entorno. Puntúa y anota los pares de estado-acción (y las secuencias de pares de estado-acción) para desarrollar una política.
Ejemplo
Considere un automóvil autónomo que necesite moverse entre el tráfico de la ciudad. Las carreteras, los patrones de tráfico, el comportamiento de los peatones y muchos otros factores pueden hacer que el entorno sea altamente dinámico y complejo. Los equipos de IA entrenan el vehículo en un entorno simulado en las etapas iniciales. El vehículo realiza acciones en función de su estado actual y recibe recompensas o penalizaciones.
Con el tiempo, al conducir millones de kilómetros en diferentes escenarios virtuales, el vehículo aprende qué acciones son las mejores para cada estado sin modelar explícitamente toda la dinámica del tráfico. Cuando se introduce en el mundo real, el vehículo utiliza la política aprendida, pero continúa perfeccionándola con nuevos datos.
¿Cuál es la diferencia entre el machine learning reforzado, supervisado y no supervisado?
Si bien el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo (RL) son todos algoritmos de ML en el campo de la IA, existen distinciones entre los tres.
Lea sobre el aprendizaje supervisado y no supervisado »
Aprendizaje reforzado frente a aprendizaje supervisado
En el aprendizaje supervisado, usted define tanto la entrada como la salida asociada esperada. Por ejemplo, puede proporcionar un conjunto de imágenes etiquetadas como perros o gatos, y luego se espera que el algoritmo identifique una nueva imagen de un animal como perro o gato.
Los algoritmos de aprendizaje supervisado aprenden patrones y relaciones entre los pares de entrada y salida. Luego, predicen los resultados en función de los nuevos datos de entrada. Requiere que un supervisor, normalmente una persona humana, etiquete cada registro de datos de un conjunto de datos de entrenamiento con un resultado.
Por el contrario, el RL tiene un objetivo final bien definido en forma de resultado deseado, pero no hay un supervisor que etiquete los datos asociados por adelantado. Durante el entrenamiento, en lugar de intentar asignar las entradas a las salidas conocidas, asigna las entradas a los posibles resultados. Al recompensar los comportamientos deseados, se da importancia a los mejores resultados.
Aprendizaje reforzado frente a aprendizaje no supervisado
Los algoritmos de aprendizaje no supervisados reciben entradas sin salidas especificadas durante el proceso de entrenamiento. Encuentran patrones y relaciones ocultos dentro de los datos utilizando medios estadísticos. Por ejemplo, puede proporcionar un conjunto de documentos y el algoritmo puede agruparlos en categorías que identifica en función de las palabras del texto. No se obtienen resultados específicos; están dentro de un rango.
Por el contrario, el RL tiene un objetivo final predeterminado. Si bien adopta un enfoque exploratorio, las exploraciones se validan y mejoran continuamente para aumentar la probabilidad de alcanzar el objetivo final. Puede enseñarse a sí mismo a alcanzar resultados muy específicos.
¿Cuáles son los desafíos del aprendizaje por refuerzo?
Si bien las aplicaciones de aprendizaje por refuerzo (RL) pueden cambiar el mundo, puede que no sea fácil implementar estos algoritmos.
Practicidad
Experimentar con sistemas de recompensas y castigos en el mundo real puede no ser práctico. Por ejemplo, probar un dron en el mundo real sin ponerlo a prueba primero en un simulador provocaría la avería de un número significativo de dispositivos aéreos. Los entornos del mundo real cambian con frecuencia, de manera significativa y con una advertencias limitadas. Puede dificultar la eficacia del algoritmo en la práctica.
Interpretabilidad
Como cualquier campo científico, la ciencia de datos también analiza las investigaciones y los hallazgos concluyentes para establecer estándares y procedimientos. Los científicos de datos prefieren saber cómo se llegó a una conclusión específica para la demostrabilidad y la replicación.
Con algoritmos de RL complejos, las razones por las que se tomó una secuencia particular de pasos pueden ser difíciles de determinar. ¿Qué acciones de una secuencia fueron las que condujeron al resultado final óptimo? Esto puede ser difícil de deducir, lo que provoca problemas de implementación.
¿Cómo puede ayudar AWS con el aprendizaje reforzado?
Amazon Web Services (AWS) tiene muchas ofertas que le ayudan a desarrollar, entrenar e implementar algoritmos de aprendizaje por refuerzo (RL) para aplicaciones del mundo real.
Con Amazon SageMaker, los desarrolladores y los científicos de datos pueden desarrollar modelos de RL escalables de forma rápida y sencilla. Combine un marco de aprendizaje profundo (como TensorFlow o Apache MXNet), un kit de herramientas de RL (como RL Coach o RLlib) y un entorno para imitar un escenario del mundo real. Podrá usar dicho escenario para crear y probar su modelo.
Con AWS RoboMaker, los desarrolladores pueden ejecutar, escalar y automatizar la simulación con algoritmos de RL para robótica sin requisitos de infraestructura.
Obtenga experiencia práctica con AWS DeepRacer, el coche de carreras totalmente autónomo a escala 1/18. Cuenta con un entorno de nube totalmente configurado que puede utilizar para entrenar sus modelos de RL y configuraciones de redes neuronales.
Cree una cuenta hoy mismo para empezar con el aprendizaje reforzado en AWS.