Quelle est la différence entre les bases de données relationnelles et non relationnelles ?




Quelle est la différence entre une base de données relationnelle et non relationnelle ?
Les bases de données relationnelles et non relationnelles sont deux méthodes de stockage de données pour les applications. Une base de données relationnelle (ou base de données SQL) stocke les données sous forme de table avec des lignes et des colonnes. Les colonnes contiennent des attributs de données et les lignes contiennent des valeurs de données. Vous pouvez lier les tables dans une base de données relationnelle pour mieux comprendre l'interconnexion entre les différents points de données. D'autre part, les bases de données non relationnelles (ou bases de données NoSQL) utilisent divers modèles de données pour accéder aux données et les gérer. Elles sont spécialement optimisées pour les applications qui nécessitent un volume de données important, une faible latence et des modèles de données flexibles, qui sont obtenus en assouplissant certaines des restrictions de cohérence des données des autres bases de données.
Comment les bases de données relationnelles stockent-elles les données ?
Les bases de données relationnelles stockent les données dans des tables comportant des colonnes et des lignes. Chaque colonne représente un attribut de données spécifique et chaque ligne représente une instance de ces données.
Vous attribuez à chaque table une clé primaire, c'est-à-dire une colonne d'identification qui identifie la table de manière unique. Vous utilisez la clé primaire pour établir des relations entre les tables. Vous l'utilisez pour relier les lignes entre les tables en tant que clé étrangère dans une autre table.
Une fois que deux tables sont connectées, vous pouvez obtenir des données à partir des deux tables à l'aide d'une seule requête. Vous écrivez des requêtes SQL pour interagir avec la base de données relationnelle.
Exemple de données stockées
Imaginons par exemple qu'un détaillant crée une table de tous ses produits. Dans cette table, vous pouvez avoir des colonnes pour les noms, les descriptions et le prix des produits. Une autre table contient des données sur les clients, leurs noms et les achats qu'ils ont effectués.
Les tables suivantes illustrent cette approche.
| Product_id (clé primaire) |
Product_name |
Product_cost |
| P1 |
Product_A |
100 USD |
| P2 |
Product_B |
50 USD |
| P3 |
Product_C |
80 USD |
| Customer_id |
Customer_name |
Item_purchased (clé étrangère) |
| C1 |
Customer_A |
P2 |
| C2 |
Customer_B |
P1 |
| C3 |
Customer_C |
P3 |
Comment les bases de données non relationnelles stockent-elles les données ?
Il existe plusieurs systèmes de bases de données non relationnelles en raison des variations dans la façon dont ils gèrent et stockent les données sans schéma. Les données sans schéma sont des données stockées sans les contraintes imposées par les bases de données relationnelles.
Ensuite, nous expliquons certains des types de bases de données non relationnelles les plus courants.
Bases de données clé-valeur
Une base de données clé-valeur stocke les données sous la forme d'un ensemble de paires clé-valeur. Dans une paire, la clé sert d'identifiant unique. Les clés et les valeurs peuvent se présenter sous toutes les formes, des objets simples aux objets composés complexes.
En savoir plus sur les bases de données clé-valeur »
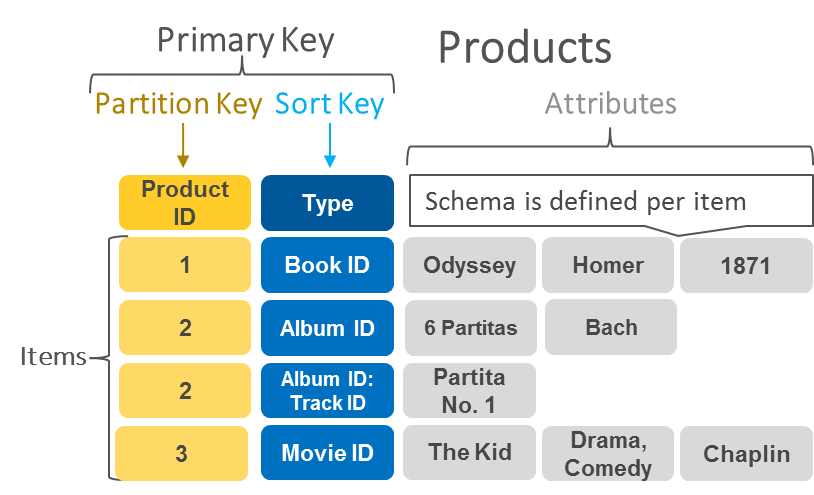
Bases de données document
Les bases de données orientées documents ont le même format de modèle de document que celui utilisé par les développeurs dans leur code d'application. Ils stockent les données sous forme d'objets JSON qui sont flexibles, semi-structurés et hiérarchiques par nature.
L'exemple suivant montre à quoi peuvent ressembler les données stockées dans une base de données document.
| { company_name : "AnyCompany", adresse : {rue : "1212 Main Street", ville : "Anytown"}, phone_number : "1-800-555-0101", secteur : ["transformation alimentaire", "appareils"] type : "privé", number_of_employees : 987 } |
En savoir plus sur les bases de données documents »
Bases de données graphiques
Les bases de données orientées graphe sont conçues pour stocker et rechercher des relations. Elles recourent à des nœuds pour stocker les entités de données, ainsi qu'à des périphéries pour stocker les relations entre les entités.
Un arc possède toujours un nœud initial, un nœud final, un type et une direction. Il peut décrire, par exemple, les relations, les actions et la propriété parents-enfants.
En savoir plus sur les bases de données orientées graphe »

Principales différences : bases de données relationnelles et non relationnelles
Les bases de données relationnelles et non relationnelles stockent et gèrent les données de manière très différente. Les sections suivantes traitent des différences spécifiques.
Structure
Les bases de données relationnelles stockent les données sous forme de tableaux et suivent des règles strictes concernant les variations de données et les relations entre les tables. Elles vous permettent de traiter des requêtes complexes sur des données structurées tout en préservant l'intégrité et la cohérence des données.
Les bases de données non relationnelles sont plus flexibles et utiles pour les données dont les exigences changent. Vous pouvez les utiliser pour stocker des images, des vidéos, des documents et d'autres contenus semi-structurés et non structurés.
Mécanisme d'intégrité des données
L'atomicité, la cohérence, l'isolation et la durabilité (ACID) font référence à la capacité de la base de données à maintenir l'intégrité des données malgré les erreurs ou les interruptions dans le traitement des données.
Un modèle de base de données relationnelle suit des propriétés ACID strictes. Cela signifie qu'un groupe d'opérations conséquentes sera toujours effectué ensemble. Si une seule opération échoue, c'est l'ensemble des opérations qui échoue. Cela garantit l'exactitude des données à tout moment.
En revanche, les bases de données non relationnelles offrent un modèle plus souple de disponibilité de base, d'état léger et de cohérence finale (BASE).
Les bases de données non relationnelles garantissent la disponibilité, mais pas la cohérence immédiate. L'état de la base de données peut changer au fil du temps et finit par devenir cohérent. Certaines bases de données non relationnelles peuvent offrir la conformité ACID en termes de performances ou autres.
Performance
Les performances des bases de données relationnelles dépendent de leur sous-système de disque. Pour améliorer les performances de la base de données, vous pouvez utiliser des SSD et optimiser le disque en le configurant avec un réseau redondant de disques indépendants (RAID). Pour obtenir des performances optimales, vous devez également optimiser les index, les structures des tables et les requêtes.
En revanche, les performances des bases de données NoSQL dépendent de la latence du réseau, de la taille du cluster matériel et de l'application appelante. Il existe plusieurs façons d'améliorer les performances d'une base de données non relationnelle :
- Augmenter la taille du cluster
- Minimiser la latence réseau
- Index et cache
Les bases de données NoSQL offrent des performances et une capacité de mise à l'échelle supérieures à celles des bases de données relationnelles pour des cas d'utilisation spécifiques.
Évolutivité
Le schéma rigide d'un système de base de données relationnelle peut poser des problèmes à grande échelle. Vous effectuez généralement une mise à l'échelle verticale en ajoutant davantage de ressources CPU ou RAM au serveur. Vous pouvez également effectuer une mise à l'échelle horizontale en dupliquant les données sur plusieurs serveurs pour les charges de travail en lecture seule. Toutefois, la mise à l'échelle horizontale pour les charges de travail en lecture/écriture nécessite des stratégies spéciales telles que le partitionnement.
En savoir plus sur le partitionnement de bases de données »
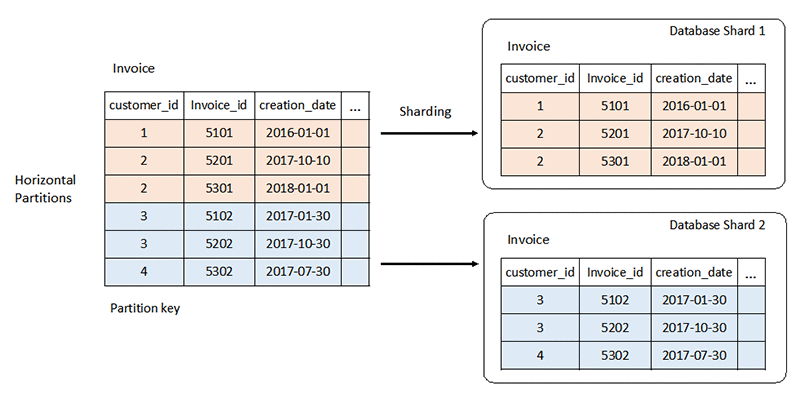
En revanche, les bases de données NoSQL sont hautement évolutives. Vous pouvez répartir leur charge de travail sur de nombreux nœuds plus facilement. Ces bases de données peuvent traiter de gros volumes de données en les partitionnant en ensembles plus petits et en les répartissant sur plusieurs nœuds.

Quand utiliser des bases de données relationnelles ou non relationnelles ?
Les bases de données relationnelles constituent le meilleur choix si vos données sont prévisibles en termes de taille, de structure et de fréquence d'accès. Vous pouvez également préférer un système de gestion de base de données relationnelle si les relations entre les entités sont importantes. Par exemple, si vous disposez d'un jeu de données volumineux doté d'une structure et de relations complexes, vous souhaitez que les relations se distinguent par leur capacité d'analyse et leur facilité d'utilisation.
En revanche, un modèle non relationnel fonctionne mieux pour stocker des données dont la forme ou la taille sont flexibles, ou qui sont susceptibles de changer à l'avenir.
Par ailleurs, dans certains cas, les relations entre les données ne s'intègrent tout simplement pas bien au format tabulaire des clés primaires et étrangères. Par exemple, pour modéliser les amis et les relations sur un réseau social, vous aurez besoin d'une table de plusieurs centaines de lignes dans une base de données relationnelle.
En revanche, cela peut être représenté par une seule ligne dans une base de données non relationnelle. L'exemple suivant montre les entrées de données d'un membre ayant quatre amis dans une base de données non relationnelle.
| Member_id Friend_id M1 M2 M1 M3 M1 M4 M1 M5 |
{nom du membre : “membre 1” amis du membre: “membre 2, membre 3, membre 4, membre 5”} |
Résumé des différences : bases de données relationnelles et non relationnelles
| Catégorie |
Base de données relationnelle |
Base de données non relationnelle |
| Modèle de données |
Tabulaire. |
Clé-valeur, document ou graphique. |
| Type de données |
Structurées. |
Structurées, semi-structurées et non structurées. |
| Intégrité des données |
Élevée avec une conformité ACID totale. |
Modèle de cohérence éventuelle. |
| Performances |
Amélioré par l'ajout de ressources au serveur. |
Amélioré par l'ajout de nœuds de serveur. |
| Dimensionnement |
La mise à l'échelle horizontale nécessite des stratégies supplémentaires de gestion des données. |
La mise à l'échelle horizontale est simple. |
Comment AWS peut-il répondre à vos exigences en matière de bases de données relationnelles et non relationnelles ?
Amazon Web Services (AWS) propose de nombreux services répondant aux exigences des bases de données relationnelles et non relationnelles.
Services AWS pour les bases de données relationnelles
Amazon Relational Database Service (Amazon RDS) est un ensemble de services gérés qui facilite la configuration, l'utilisation et la mise à l'échelle d'une base de données relationnelle dans le cloud. Les bases de données cloud offrent de nombreux avantages tels que les performances, la mise à l'échelle et la rentabilité. Vous pouvez utiliser des moteurs de base de données relationnelle comme ceux-ci :
- Amazon RDS for SQL Server pour déployer plusieurs éditions de SQL Server (2014, 2016, 2017 et 2019)
- Amazon RDS for MySQL pour prendre en charge les versions 5.7 et 8.0 de MySQL Community Edition
- Amazon RDS for MariaDB pour prendre en charge les versions 10.3, 10.4, 10.5 et 10.6 de MariaDB Server
De plus, Amazon RDS for Oracle propose deux modèles de licence différents, ce qui vous évite d'acheter séparément des licences Oracle si vous n'en avez pas.
Services AWS pour les bases de données non relationnelles
AWS propose également plusieurs services de base de données NoSQL pour répondre à tous vos besoins en la matière. Voici quelques exemples :
- Amazon DynamoDB est un service de base de données clé-valeur qui fournit une latence constante de quelques millisecondes pour les charges de travail, quelle que soit l'échelle.
- Amazon DocumentDB (compatible avec MongoDB) est une base de données populaire orientée documents, dotée d'API puissantes et intuitives pour un développement flexible et itératif.
- Amazon MemoryDB est un service de base de données en mémoire durable. Il offre une latence de lecture et d'écriture de l'ordre de quelques microsecondes pour des performances ultra rapides.
- Amazon Neptune est un service de base de données orientée graphe entièrement géré qui permet de créer et d'exécuter des applications graphiques très performantes.
- Amazon OpenSearch Service est conçu pour fournir des visualisations et des analyses en temps quasi réel de données générées par machine.
Commencez à utiliser des bases de données relationnelles et non relationnelles sur AWS en créant un compte dès aujourd'hui.