



Qu'est-ce que le boosting en machine learning ?
Le boosting est une méthode utilisée dans le machine learning pour réduire les erreurs dans l’analyse prédictive de données. Les scientifiques des données utilisent des données étiquetées pour entraîner des logiciels de machine learning (appelés modèles de machine learning) à faire des prédiction sur des données non étiquetées. Un modèle de machine learning unique peut faire des erreurs de prédiction selon la précision du jeu de données d'entraînement. Par exemple, si un modèle d'identification de chats n'a été entraîné que sur des images de chats blancs, il peut occasionnellement faire des erreurs lors de l'identification d'un chat noir. Le boosting s'efforce de résoudre ce problème en entraînant successivement plusieurs modèles afin d'améliorer la précision du système global.
Pourquoi le boosting est-il important ?
Le boosting améliore la précision et les performances prédictives des modèles de machine learning en convertissant plusieurs apprenants faibles en un seul modèle d'apprentissage fort. Les modèles de machine learning peuvent être des apprenants faibles ou des apprenants forts :
Apprenants faibles
Les apprenants faibles ont une faible précision de prédiction, semblable à celle des devinettes aléatoires. Ils sont enclins à la suradaptation, c'est-à-dire qu'ils ne peuvent pas classer des données qui varient trop par rapport à leur ensemble de données d'origine. Par exemple, si vous entraînez le modèle à identifier les chats comme des animaux aux oreilles pointues, il pourrait ne pas reconnaître un chat dont les oreilles sont recourbées.
Apprenants forts
Les apprenants forts ont une précision de prédiction plus élevée. Le boosting convertit un système d'apprenants faibles en un système unique d'apprentissage fort. Par exemple, pour identifier l'image du chat, il combine un apprenant faible qui devine les oreilles pointues et un autre apprenant qui devine les yeux en forme de chat. Après avoir analysé l'image de l'animal pour détecter les oreilles pointues, le système l'analyse à nouveau pour détecter les yeux en forme de chat. Cela améliore la précision globale du système.
Comment fonctionne le boosting ?
Pour comprendre le fonctionnement du boosting, décrivons comment les modèles de machine learning prennent des décisions. Bien qu'il existe de nombreuses variations dans l'implémentation, les scientifiques des données utilisent souvent le boosting avec des algorithmes d'arbre de décision :
Arbres de décision
Les arbres de décision sont des structures de données en machine learning qui fonctionnent en divisant l'ensemble de données en sous-ensembles de plus en plus petits selon leurs caractéristiques. L'idée est que les arbres de décision divisent les données de manière répétée jusqu'à ce qu'il ne reste qu'une seule classe. Par exemple, l'arbre peut poser une série de questions par oui ou par non et diviser les données en catégories à chaque étape.
Méthode d'ensemble du boosting
Le boosting crée un modèle d'ensemble en combinant plusieurs arbres de décision faibles de manière séquentielle. Il attribue des poids à la sortie des arbres individuels. Ensuite, il accorde aux classifications incorrectes du premier arbre de décision un poids plus élevé et une entrée dans l'arbre suivant. Après de nombreux cycles, la méthode de boosting combine ces règles faibles en une règle unique de prédiction forte.
Boosting par rapport bagging
Boosting et bagging (bootstrap aggregating) sont les deux méthodes d'ensemble courantes qui améliorent la précision des prédictions. La principale différence entre ces méthodes d'apprentissage est la méthode d'entraînement. Dans le bagging, les scientifiques des données améliorent la précision des apprenants faibles en entraînant plusieurs d'entre eux en même temps sur plusieurs jeux de données. En revanche, le boosting entraîne les apprenants faibles les uns après les autres.
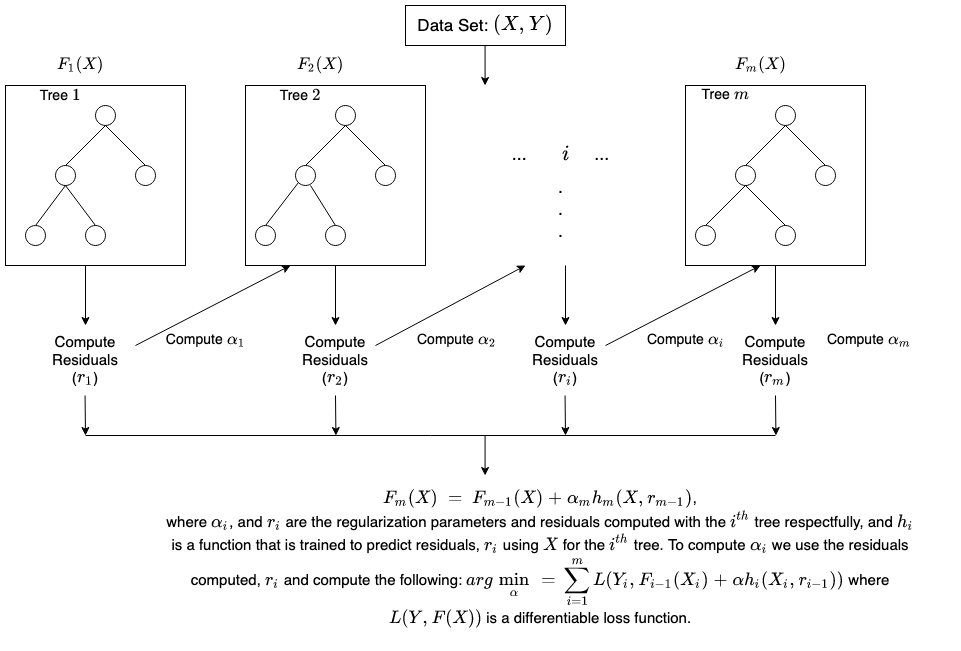
Comment se déroule l'entraînement dans le boosting ?
La méthode d'entraînement varie en fonction du type de processus de boosting appelé algorithme de boosting. Cependant, un algorithme suit les étapes générales suivantes pour entraîner le modèle de boosting :
Étape 1
L'algorithme de boosting attribue un poids égal à chaque échantillon de données. Il alimente en données le premier modèle machine, appelé algorithme de base. L'algorithme de base effectue des prédictions pour chaque échantillon de données.
Étape 2
L'algorithme de boosting évalue les prédictions du modèle et augmente le poids des échantillons présentant une erreur plus importante. Il attribue également un poids en fonction des performances du modèle. Un modèle qui produit d'excellentes prédictions aura une grande influence sur la décision finale.
Étape 3
L'algorithme transmet les données pondérées à l'arbre de décision suivant.
Étape 4
L'algorithme répète les étapes 2 et 3 jusqu'à ce que les instances d'erreurs d'entraînement soient inférieures à un certain seuil.
Quels sont les types de boosting ?
Voici les trois principaux types de boosting :
Boosting adaptatif
Le boosting adaptatif (AdaBoost) est l'un des premiers modèles de boosting développés. Il s'adapte et tente de s'autocorriger à chaque itération du processus de boosting.
AdaBoost donne initialement le même poids à chaque ensemble de données. Ensuite, il ajuste automatiquement les poids des points de données après chaque arbre de décision. Il donne plus de poids aux éléments mal classés afin de les corriger pour le prochain tour. Il répète le processus jusqu'à ce que l'erreur résiduelle, ou la différence entre les valeurs réelles et prévues, tombe sous un seuil acceptable.
Vous pouvez utiliser AdaBoost avec de nombreux prédicteurs, et il n'est généralement pas aussi sensible que les autres algorithmes de boosting. Cette approche ne fonctionne pas bien lorsqu'il existe une corrélation entre les caractéristiques ou une forte dimensionnalité des données. Dans l'ensemble, AdaBoost est un type de boosting approprié pour les problèmes de classification.
Boosting de gradient
Le boosting de gradient (GB), également appelé amplification de gradient, est similaire à AdaBoost dans la mesure où il s'agit également d'une technique d'entraînement séquentiel. La différence entre AdaBoost et GB est que GB ne donne pas plus de poids aux éléments mal classés. Au lieu de cela, le logiciel GB optimise la fonction de perte en générant des apprenants de base de manière séquentielle, de sorte que l'apprenant de base actuel soit toujours plus efficace que le précédent. Cette méthode tente de générer des résultats précis au départ au lieu de corriger les erreurs tout au long du processus, comme AdaBoost. Pour cette raison, le logiciel GB peut conduire à des résultats plus précis. Le boosting de gradient peut aider à résoudre les problèmes de classification et de régression.
Boosting de gradient extrême
Le boosting de gradient extrême (XGBoost, Extreme Gradient Boosting) améliore le boosting de gradient en termes de vitesse de calcul et d'échelle de plusieurs façons. XGBoost utilise plusieurs cœurs sur le CPU afin que l'apprentissage puisse se faire en parallèle pendant l'entraînement. Il s'agit d'un algorithme de boosting qui peut traiter de vastes jeux de données, ce qui le rend attrayant pour les applications de big data. Les principales caractéristiques de XGBoost sont la parallélisation, le calcul distribué, l'optimisation du cache et le traitement hors du cœur.
Quels sont les avantages du boosting ?
Le boosting offre les avantages majeurs suivants :
Facilité d'implémentation
Le boosting a des algorithmes faciles à comprendre et à interpréter qui apprennent de leurs erreurs. Ces algorithmes ne nécessitent aucun prétraitement des données, et ils disposent de routines intégrées pour traiter les données manquantes. En outre, la plupart des langages disposent de bibliothèques intégrées permettant d'implémenter des algorithmes de boosting avec de nombreux paramètres permettant d'affiner les performances.
Réduction des biais
Les biais sont la présence d'incertitude ou d'inexactitude dans les résultats du machine learning. Les algorithmes de boosting combinent plusieurs apprenants faibles dans une méthode séquentielle, qui améliore itérativement les observations. Cette approche permet de réduire les biais élevés qui sont courants dans les modèles de machine learning.
Efficacité de calcul
Les algorithmes de boosting donnent la priorité aux caractéristiques qui augmentent la précision prédictive pendant l'entraînement. Ils peuvent aider à réduire les attributs des données et à traiter efficacement les grands jeux de données.
Quels sont les défis du boosting ?
Voici les limites courantes des modes de boosting :
Vulnérabilité aux données aberrantes
Les modèles de boosting sont vulnérables aux valeurs aberrantes ou aux valeurs de données qui sont différentes du reste du jeu de données. Étant donné que chaque modèle tente de corriger les défauts de son prédécesseur, les valeurs aberrantes peuvent fausser considérablement les résultats.
Implémentation en temps réel
Vous pourriez également trouver difficile d'utiliser le boosting pour une mise en œuvre en temps réel, car l'algorithme est plus complexe que les autres processus. Les méthodes de boosting ont une grande capacité d'adaptation. Vous pouvez donc utiliser une grande variété de paramètres de modèle qui affectent immédiatement les performances du modèle.
Comment les services AWS peuvent-ils vous aider en matière de boosting ?
Les services de réseaux AWS sont conçus pour fournir aux entreprises :
Amazon SageMaker
Amazon SageMaker réunit un vaste ensemble de capacités spécialement conçues pour le machine learning. Vous pouvez l'utiliser pour préparer, créer, entraîner et déployer rapidement des modèles de machine learning de haute qualité.
Amazon SageMaker Canvas
Amazon SageMaker Canvas élimine la lourde tâche de création de modèles de machine learning et vous aide à créer et entraîner automatiquement des modèles basés sur vos données. Avec SageMaker Canvas, vous fournissez un jeu de données tabulaire et sélectionnez la colonne cible à prédire, qui peut être un nombre ou une catégorie. SageMaker Autopilot explore automatiquement différentes solutions pour trouver le meilleur modèle. Ensuite, vous déployez directement le modèle en production en un seul clic, ou vous itérez sur les solutions recommandées avec Amazon SageMaker Studio pour améliorer encore la qualité du modèle.
Amazon SageMaker Model Monitor
L’entraînement de modèle Amazon SageMaker permet d’optimiser facilement les modèles de machine learning en capturant les métriques d’entraînement en temps réel et en envoyant des alertes lorsqu’il détecte des erreurs. Cela vous permet de corriger immédiatement les prédictions inexactes du modèle, telles que l'identification incorrecte d'une image.
Amazon SageMaker offre des méthodes rapides et faciles pour entraîner de grands modèles et jeux de données de deep learning. Les bibliothèques d’apprentissage distribuées SageMaker entraînent plus rapidement les grands jeux de données.
Commencez avec Amazon SageMaker en créant un compte AWS aujourd'hui.