Amazon SageMaker Data Wrangler
機械学習用のデータを準備するための極めて迅速かつ簡単な方法 - SageMaker Canvas で使用可能になぜ、SageMaker Data Wrangler?
Amazon SageMaker Data Wrangler は、表形式、画像、テキストデータの準備にかかる時間を数週間から数分に短縮します。SageMaker Data Wrangler を利用すると、視覚的および自然言語インターフェイスを通じて、データ準備と特徴量エンジニアリングを簡素化できます。コードを記述することなく、SQL と、300 を超える組み込み変換を使用して、データを迅速に選択、インポート、変換できます。データタイプ全体で異常を検出し、モデルのパフォーマンスを推定するために、直感的なデータ品質レポートを生成できます。ペタバイト規模のデータを処理するためにスケールできます。
SageMaker データラングラーのメリット
仕組み
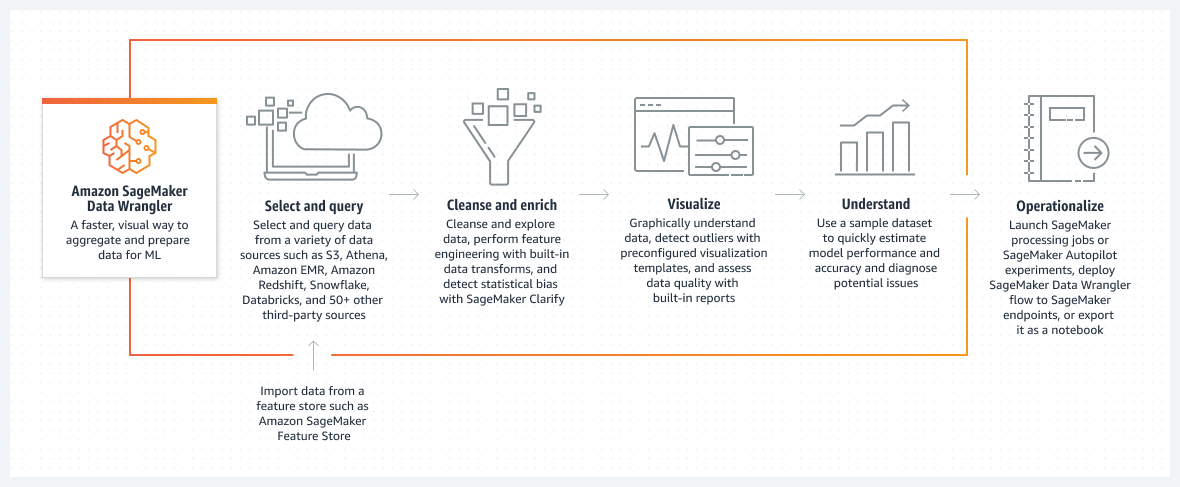
仕組み

タイトル 1: Amazon SageMaker Data Wrangler
説明テキスト: より速く、より視覚的に、ML のためのデータを集約し準備する方法
タイトル 2: 選択 & クエリ
説明テキスト: Amazon S3、Athena、Amazon EMR、Amazon Redshift、Snowflake、Databricks、その他 50 以上のサードパーティソースなどの様々なデータソースからデータを選択しクエリします
サブの説明: Amazon SageMaker Feature Store などのフィーチャーストアからデータをインポート
タイトル 3: クレンジングとエンリッチ
説明テキスト: SageMaker Clarify は、データのクレンジングと探索、ビルトインデータ変換による特徴量エンジニアリングの実行、統計的バイアスの検出を行うことができます。
タイトル 4: ビジュアライズ
説明テキスト: データをグラフィカルに理解し、あらかじめ設定された可視化テンプレートで外れ値を検出し、内蔵のレポートでデータの品質を評価する。
タイトル 5: 理解する
説明テキスト: サンプルデータセットを使用して、モデルのパフォーマンスと精度を迅速に見積もり、潜在的な問題を診断します。
タイトル 6: オペレーショナライズ
説明テキスト SageMaker 処理ジョブや SageMaker Autopilot 実験の起動、SageMaker Data Wrangler フローの SageMaker エンドポイントへのデプロイ、ノートブックとしての書き出しを行います。
データへのアクセス、選択、クエリの高速化
SageMaker Data Wrangler を使用すると、S3、Athena、Redshift などの Amazon サービスや 50 以上のサードパーティーソースから、表形式、テキスト、および画像データにすばやくアクセスできます。ビジュアルクエリビルダーでデータを選択したり、SQL クエリを記述したり、CSV や Parquet などのさまざまな形式でデータデータを直接インポートしたりできます。

データインサイトの生成とデータ品質の把握
SageMaker Data Wrangler は、データ品質 (欠損値、重複行、データ型など) を自動的に検証し、データの異常 (外れ値、クラスの不均衡、データ漏洩など) を検出するのに役立つデータ品質とインサイトレポートを提供します。データ品質を効果的に検証できれば、ML モデルトレーニング用のデータセットを処理するためにドメインナレッジを迅速に適用することができます。

視覚化でデータを理解する
SageMaker Data Wrangler は、ヒストグラム、散布図、特徴量の重要度、相関などの堅牢なビルトインビジュアライゼーションテンプレートを使用してデータを理解するのに役立ちます。さまざまなデータタイプの異常を検出し、データ品質を向上させるためのレコメンデーションを提供する直感的なデータ品質レポートにより、データ探索を加速します。

データをより効率的に変換する
SageMaker Data Wrangler には、300 種類以上の PySpark 変換があらかじめ組み込まれています。また、表データ、時系列データ、テキストデータ、画像データをコーディングなしで作成するための自然言語インターフェイスも用意されています。テキストのベクトル化、日時の特徴付け、エンコーディング、データの調整、画像拡張などの一般的なユースケースに対応します。PySpark、SQL、Pandas でカスタム変換を作成したり、自然言語インターフェイスを使用してコードを生成したりすることもできます。コードスニペットの組み込みライブラリにより、カスタム変換を簡単に記述できます。

データの予測力を理解する
SageMaker Data Wrangler は、データの予測力を推定するための Quick Model 分析を行います。モデルの推定精度、特徴量の重要度、混同行列を取得できるため、モデルをトレーニングする前にデータ品質を検証できます。

ML データ準備ワークフローの自動化とデプロイ
SageMaker Data Wrangler を使用すると、PySpark をコーディングしたりクラスターをスピンアップしたりすることなく、ペタバイト規模のデータを準備できるようにスケールできます。UI から直接処理ジョブを起動することができ、さらにデータを SageMaker Feature Store にエクスポートしたり、SageMaker パイプラインと統合したりして、データ準備を ML ワークフローに統合することもできます。データフローを Jupyter Notebook または Python スクリプトとしてエクスポートして、データ準備手順をプログラムでレプリケートすることもできます。

お客様
「INVISTA では、変革を推進し、世界中のお客様に利益をもたらす製品とテクノロジーの開発を目指しています。ML はカスタマーエクスペリエンスを向上させる方法だと考えています。しかし、データセットが数億行に及ぶため、データの準備、ML モデルの大規模な開発、デプロイ、管理にとって有用なソリューションが必要でした。Amazon SageMaker Data Wrangler を使用することにより、データをインタラクティブに選択、クリーニング、探索、把握できるようになり、データサイエンスチームは数億行に及ぶデータセットにも簡単にスケールできる特徴量エンジニアリングパイプラインを作成できるようになりました。Amazon SageMaker Data Wrangler を使用すれば、ML ワークフローをより迅速に運用できます」
INVISTA、元リードデータサイエンティスト、Caleb Wilkinson 氏
「3M は ML を使用して、サンドペーパーなどの実証済みの製品を改善し、ヘルスケアを含む他のいくつかの分野でイノベーションを推進しています。当社では、3M のより多くの領域に ML をスケールすることを計画しているため、データとモデルの量は急速に増加し、毎年 2 倍になっています。SageMaker の新機能はスケールに役立つため、当社にメリットをもたらしてくれるものであると確信しています。Amazon SageMaker Data Wrangler を使用すると、モデルトレーニング用のデータの準備がはるかに簡単になり、Amazon SageMaker Feature Store を使用すると、同じモデル特徴量を何度も作成する必要がなくなります。最後に、Amazon SageMaker Pipelines は、データの準備、モデルの構築、およびモデルのデプロイをエンドツーエンドのワークフローに自動化するのに役立つため、モデルの市場投入までの時間を短縮できます。当社の研究者たちは、3M の科学の新たなスピードを活用することを楽しみにしています」
3M Corporate Systems Research Lab、元テクニカルディレクター、David Frazee 氏
「Amazon SageMaker Data Wrangler を使用すると、新製品を市場に投入するために必要な ML データ準備のプロセスを加速する変換ツールの豊富なコレクションを使用して、すぐに全力でデータ準備のニーズに対応することが可能となります。そして、当社のクライアントのニーズを満たす測定可能かつ持続可能な結果を数か月ではなく数日で提供することを可能にする、デプロイされたモデルをスケールする速度により、当社のお客様は恩恵を受けます」
Deloitte、プリンシパル、AI Ecosystems and Platforms Leader、Frank Farrall 氏
「当社のエンジニアリングチームは AWS プレミアコンサルティングパートナーとして AWS と緊密に連携して、お客様が運用効率を継続的に改善できるように革新的なソリューションを構築しています。ML は当社の革新的なソリューションの中核となりますが、データ準備ワークフローには高度なデータ準備技術が含まれているため、本稼働環境で運用できるようになるまでかなりの時間がかかります。データサイエンティストは、Amazon SageMaker Data Wrangler を使用して、データの選択、消去、探索、視覚化など、データ準備ワークフローの各ステップを完了することができます。これにより、データ準備プロセスを加速し、ML 用のデータを簡単に用意することができます。Amazon SageMaker Data Wrangler を使用すれば、ML 用のデータをより迅速に準備できます」
NRI 日本、常務執行役員、大元成和氏
「Population Health Management 市場における当社の活動の場は、より多くの医療費の支払者、医療提供者、薬剤給付管理者、およびその他の医療機関に拡大し続けているため、クレームデータ、登録データ、および薬局データなどのデータを ML モデルに供給するデータソースのエンドツーエンドプロセスを自動化するソリューションが必要でした。Amazon SageMaker Data Wrangler を使用することで、検証と再利用が容易な一連のワークフローを使用して、ML のためにデータを集約して準備するのにかかる時間を短縮できます。これにより、モデルの配信時間と質が劇的に向上し、データサイエンティストがより多くの成果を生み出し、データの準備にかかる時間が 50% 近く短縮されました。さらに、SageMaker Data Wrangler は、複数の ML のイテレーションと大幅な GPU 時間を節約し、薬局、診断コード、ER 訪問、および患者の入院だけでなく、人口統計学的およびその他の社会的決定要因など、何千もの特徴量を備えたデータマートを構築できるため、クライアントのためのエンドツーエンドプロセス全体を高速化するのに役立ちました。SageMaker Data Wrangler を使用すると、トレーニングデータセットを構築するために優れた効率でデータを変換し、ML モデルを実行する前にデータセットに関するデータインサイトを生成し、大規模な推論/予測のためにリアルワールドデータを準備できます」
Equilibrium Point IoT、CEO、Lucas Merrow 氏